함수형 프로그래밍과 JavaScript ES6+ 8. 지연성 2 (1)
17 Mar 2020 | javascript functional-programming ES6inflearn의 함수형 프로그래밍과 JavaScript ES6+를 보고 공부한 것을 정리합니다.
결과를 만드는 함수 reduce, take
map, filter 같은 함수들은 배열이나 이터러블한 값의 안쪽에 있는 원소들에게 함수들을 합성해놓는 역할을 한다. 그러나 reduce나 take와 같은 함수들은 그 안에 있는 값들을 꺼내서 더해버린다. 즉, 최종적으로 어떤 결과를 만드는 함수이다.
a, b, c, d 이렇게 값을 가지고 있는 배열이 있다면 a와 b를 꺼내어 더해버리는 것과 같은 방식으로, 배열이나 이터러블 형태의 값을 유지시키는 것이 아니라 실제로 그 안에 있는 값을 꺼내서 깨뜨려야 하기 때문이다.
map, filter 같은 함수들은 지연성을 가질 수 있다. 그러나 reduce 같은 함수는 실제로 연산의 시작을 알리는 함수이다. 함수들을 만들 때 map 계열 함수를 연속적으로 사용하다가 특정 지점에서 reduce 같은 함수를 통해 안에 배열이나 이터러블 형태를 깨뜨려 함수를 종료하거나 그 다음 로직을 만드는 등의 역할을 한다.
함수형 프로그래밍을 할 때도 a로부터 b라는 값을 만들고자 할 때, a를 받아서 map, filter 등을 반복하다가 reduce로 최종적으로 값을 만들어 리턴하겠다고 사고하면서 프로그래밍을 하면 좋다.
take도 값을 두 개만 yield하기로 약속하는 식으로 지연성을 줄 수는 있다. 그러나 실제로 몇 개로 떨어질지 모르는 배열에서 특정 개수의 배열로 축약하고 완성을 짓는 성질을 가지고 있기 때문에, take 자체가 지연성을 가지기보다는 take를 한 시점에서 연산이 이루어지는 것이 프로그래밍을 할 때에 보다 확실하고 편리하다. 또, 변수를 여러 군데에 할당할 때에도 더 용이하다.
reduce
객체로부터 url의 querystring을 얻어내는 코드를 작성해볼 것이다.
const queryStr = obj => go(
obj,
Object.entries
);
log(queryStr({ limit: 10, offset: 10, type: 'notice' }));

entries라는 메서드를 사용하면 key value 형태로 출력할 수 있다.
const queryStr = obj => go(
obj,
Object.entries,
map(([k, v]) => `${k}=${v}`)
);

const queryStr = obj => go(
obj,
Object.entries,
map(([k, v]) => `${k}=${v}`),
reduce((a, b) => `${a}&${b}`)
);
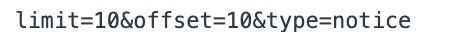
마지막에 reduce로 축약하여 결과를 완성짓는다.
obj를 받아서 그대로 obj를 전달하고 있기 때문에 pipe로 변경할 수 있다.
const queryStr = pipe(
Object.entries,
map(([k, v]) => `${k}=${v}`),
reduce((a, b) => `${a}&${b}`)
);
이 함수에서 reduce가 하는 연산은 Array.prototype.join함수와 비슷하다. join은 Array.prototype에만 있는 함수이지만, reduce는 이터러블 객체를 모두 순회하면서 축약할 수 있기 때문에 더 다형성이 높은 join 함수를 만들 수 있다. 좀더 간결하고, 재사용 가능한 join함수를 reduce를 통해 만들어볼 것이다.
const join = curry((sep = ',', iter) =>
reduce((a, b) => `${a}${sep}${b}`, iter));
const queryStr = pipe(
Object.entries,
map(([k, v]) => `${k}=${v}`),
join('&')
);
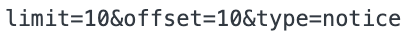
원래의 join은 배열에 특정 seperator를 줘서 문자열로 만들 수 있는 메서드이다. 다만, 앞에 있는 객체가 반드시 배열이어야 사용이 가능하다.

그런데 우리가 만든 join은 배열이 아니어도 사용 가능하다.
받는 값을 reduce를 통해 축약하기 때문이다.
function *a() {
yield 10;
yield 11;
yield 12;
yield 13;
}
log(join(' - ', a()));

이 join 함수는 훨씬 조합성이 높다. 또한 reduce를 통해 만들었기 때문에, 이터러블 프로토콜을 따른다. 즉, join에게 가기 전의 값들을 지연시킬 수 있다.
join연산 전의 객체를 출력해보면 이미 다 계산을 마치고 만들어진 배열이다.

L.map을 사용하여 아직 연산이 되지 않은 상태의 이터레이터를 join에게 주어, join이 안쪽에서 next를 통해 결과를 그때그때 연산하는 식으로 미룰 수도 있다.
const queryStr = pipe(
Object.entries,
L.map(([k, v]) => `${k}=${v}`),
a => (console.log(a), a), // 중간 객체 출력
join('&')
);

또, 앞의 entries 메서드 역시 지연성을 가지도록 할 수 있다.
L.entries = function *(obj) {
for (const k in obj) yield [k, obj[k]];
};

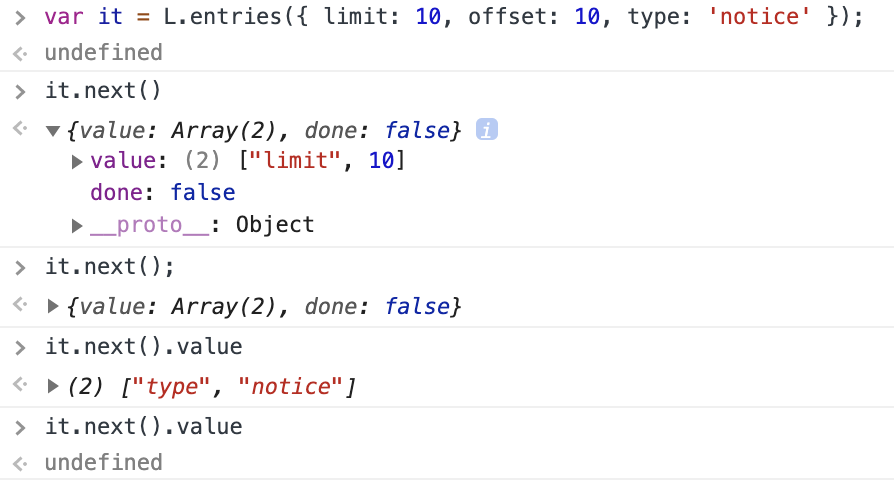
const queryStr = pipe(
L.entries,
a => (console.log(a), a), // 중간 객체 출력
L.map(([k, v]) => `${k}=${v}`),
join('&')
);
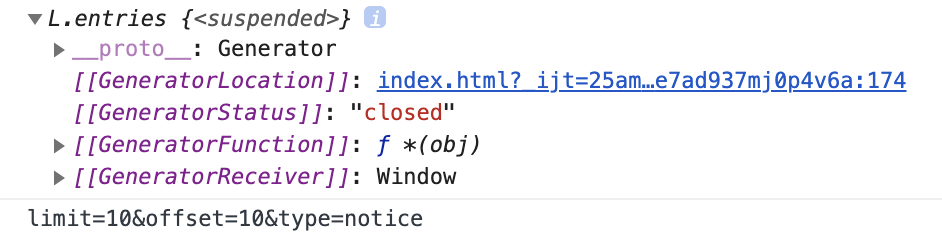
이렇게, Array.prototype.join보다 훨씬 다형성이 높은 join함수를 만들었다. 이는 객체지향의 클래스 기반 추상화보다 훨씬 유연한 방식이라고 할 수 있다.
take
join은 reduce 계열, 즉 reduce로 만들 수 있는 함수이다. 반면 L.entries는 map 계열의 함수이다.
함수형 프로그래밍은 어떤 계열 혹은 계보를 가지는 식으로 함수를 만들 수 있다.
이번에는 find 함수를 take를 통해 만들어볼 것이다.
const users = [
{ age: 32 },
{ age: 31 },
{ age: 37 },
{ age: 32 },
{ age: 28 },
{ age: 25 },
{ age: 32 },
{ age: 31 },
{ age: 37 }
]
이 users에서 첫번째로 특정 조건을 만족하는 객체를 뽑아내는 함수를 find라는 이름으로 만들어볼 것이다.
const find = (f, iter) => go(
iter,
filter(f),
);
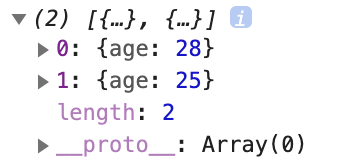
우선 조건에 맞는 값을 모두 꺼내도록 만든다.
const find = (f, iter) => go(
iter,
filter(f),
take(1),
([a]) => a
);
log(find(u => u.age < 30, users));
take함수를 통해 하나만 꺼내도록 하고, 배열을 깨서 꺼내준다.

중간 과정을 확인해보면, 이 함수가 결국 리턴하는 것은 하나의 결과이지만 내부적으로는 배열의 모든 원소를 확인하고 있다.
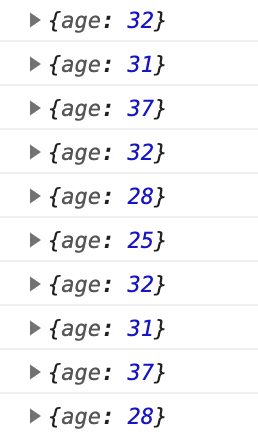
그 후에도 두 객체를 만들어서 리턴한다.
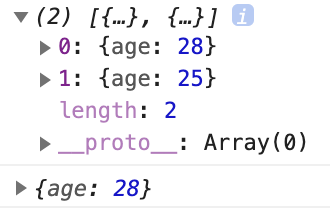
즉, 효율적이지 못한 상태라고 할 수 있다.
여기에서 지연성을 주면 미뤄져 있는 결과를 얻게 되고, take 안에서 하나씩 꺼내 보면서 해당하는 값을 하나 찾으면 그만하고 결과를 반환한다.
const find = (f, iter) => go(
iter,
L.filter(f),
take(1),
([a]) => a
);
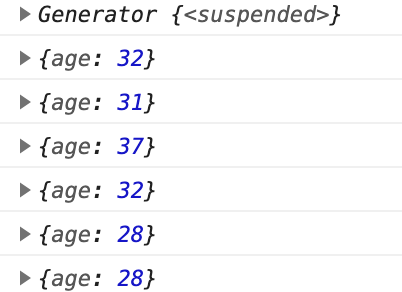
하나의 값이 꺼내지면 더 이상 필터링을 하지 않도록 미뤄주면 효율적인 코딩이 가능해진다.
즉, find는 받은 모든 값을 조건에 맞추어 필터링하되, 하나가 꺼내질 때까지만 필터링한 후에 구조분해하여 결과를 주는 함수이다. 이 함수 안에는 for문도 없고, 이터러블 객체를 해석하거나 돌리거나 if문을 걸지도 않기 때문에 이해하기 쉽다.
이터러블 객체를 넣어서 filter를 하다가 하나가 꺼내지면 구조분해하여 리턴
나중에 이 find 함수를 다시 보더라도 이해하기가 쉬워진다.
다음과 같이 curry로 묶을 수도 있다.
const find = curry((f, iter) => go(
iter,
L.filter(f),
take(1), // 하나만 꺼내도록
([a]) => a // 배열을 깨서 꺼내줌
));
find가 먼저 받는 값이 이터러블이기 때문에, 연산을 완료한 값을 주어도 사용이 가능하다. 또, 결과를 미뤄놓은 값 (L.map)을 주어도 한번 더 미뤄 연산하면서 결과를 만들 수 있다.
go(
users,
L.map(u => u.age),
find(n => n < 30),
log
)

L.map, L.filter로 map과 filter 만들기
log(map(a => a + 10, range(4)));
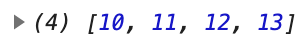
위의 range를 L.range로 바꾸어도 동작한다.
map의 Symbol.iterator를 통해서 이터러블 객체를 이터레이터로 만들어 사용하고 있기 때문이다.
const map = curry((f, iter) => go(
iter,
L.map(f)
));
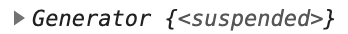
앞으로 평가할 준비가 되어 있는 지연된 값이 된다.
const map = curry((f, iter) => go(
iter,
L.map(f),
take(Infinity)
));
앞에서 만들어지는 map이 length와 관계없이 모두 결과값을 만들게 된다.
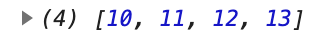
pipe를 통해 더 간결하게 만들 수도 있다.
const map = curry(pipe(L.map, take(Infinity)));
filter도 같은 방식으로 가능하다.
const filter = curry(pipe(L.filter, take(Infinity)));
log(filter(a => a % 2, range(4)));
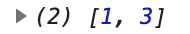
여기서 take(Infinity)라는 같은 코드를 사용하기 때문에, 다음과 같이 축약할 수 있다.
const map = curry(pipe(L.map, takeAll));
const filter = curry(pipe(L.filter, takeAll));
Comments